Anurag Ajay | Graduation Date: 06/01/2023
PI Lead: Pulkit Agrawal, MIT EECS Assistant Professor
Anurag Ajay is a Ph.D. student in EECS at MIT CSAIL advised by Professor Pulkit Agrawal. He received his S.M. in EECS from MIT advised by Professor Leslie Kaelbling and Professor Josh Tenenbaum. his research goal is to design algorithms that can enable agents to continuously interact, learn, and perform complex tasks in their environments. He is interested in learning Visuomotor Priors for Behavior
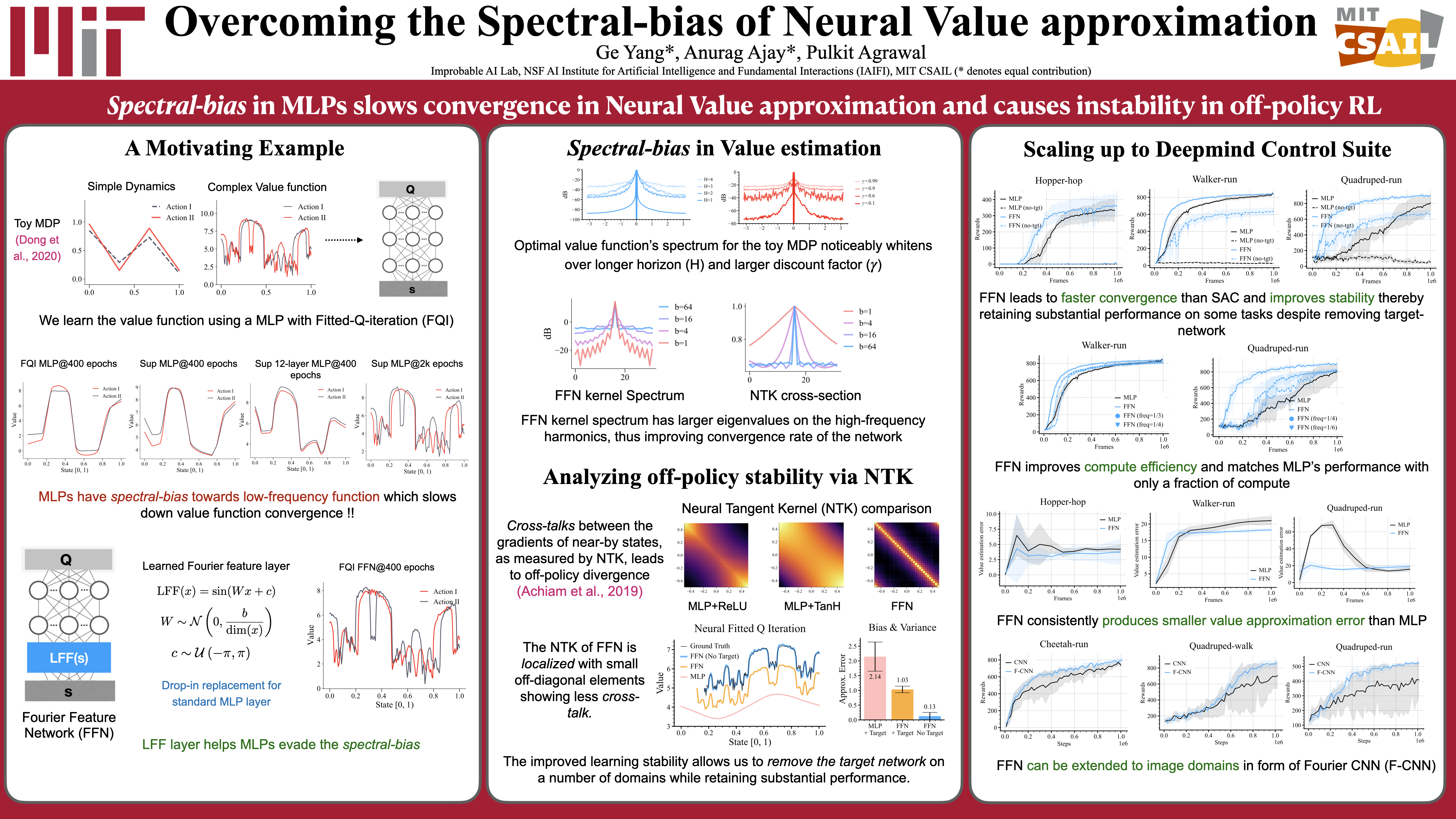
Abstract: Value approximation using deep neural networks is at the heart of off-policy deep reinforcement learning, and is often the primary module that provides learning signals to the rest of the algorithm. While multi-layer perceptrons are universal function approximators, recent works in neural kernel regression suggest the presence of a spectral bias, where fitting high-frequency components of the value function requires exponentially more gradient update steps than the low- frequency ones. In this work, we re-examine off-policy reinforcement learning through the lens of kernel regression and propose to overcome such bias via a composite neural tangent kernel. With just a single line-change, our approach, the Fourier feature networks (FFN) produce state-of-the- art performance on challenging continuous control domains with only a fraction of the compute. Faster convergence and better off-policy stability also make it possible to remove the target network without suffering catastrophic divergences, which further reduces TD(0)’s bias to over-estimate the value.
Tanner Andrulis | Graduation Date: 05/01/2028
PI Leads: Joel Emer, MIT CSAIL Professor of the Practice | Vivienne Sze, MIT EECS Associate Professor

Tanner Andrulis received B.S. degrees in Computer Engineering and Math from Purdue University in 2021. He is currently pursuing the Ph.D. degree under the supervision of Professor Vivienne Sze and Professor Joel Emer. His research focuses on the design and modeling of tensor accelerators, especially emerging analog and processing-in-memory architectures. Tanner was a recipient of the MIT Presidential Fellowship in 2021.
Abstract: Memory costs are a growing challenge in deep neural network (DNN) accelerator design. Increasing DNN sizes paired with high costs of data movement and memory bottleneck DNN accelerators. In fact, recent architectures dedicate most of their area to memory and most of their energy to data movement. In response, there is a growing interest in processing-inmemory (PIM) systems that minimize data movement by performing compute and memory in-place. These systems skip data transfer costs of large DNNs for huge efficiency gains. Some of the most promising candidates for building PIM accelerators are memristive non-volatile-memory (NVM) devices. These offer extremely high density and enable entire DNNs to be stored on-chip. Additionally, their crossbar structures enable parallel and efficient analog multiplyaccumulate (MAC) operations, the core computations of DNNs.
Tao Chen | Graduation Date: 05/29/2024
PI Lead: Pulkit Agrawal, MIT EECS Assistant Professor
Tao Chen is a Ph.D. student in EECS at MIT CSAIL. He received his master’s degree in robotics at CMU and bachelor’s degree in mechanical engineering at Shanghai Jiao Tong University. His research interests include robot learning, manipulation, locomotion, and navigation. His work on dexterous manipulation won the best paper award at Conference on Robot Learning (CoRL) 2021. His works have been published in top-tier AI and robotics conferences such as NeurIPS, ICLR, RSS, ICRA, CoRL, and were featured in many popular press outlets, including MIT News, WIRED, AZO Robotics, AIHub, etc.
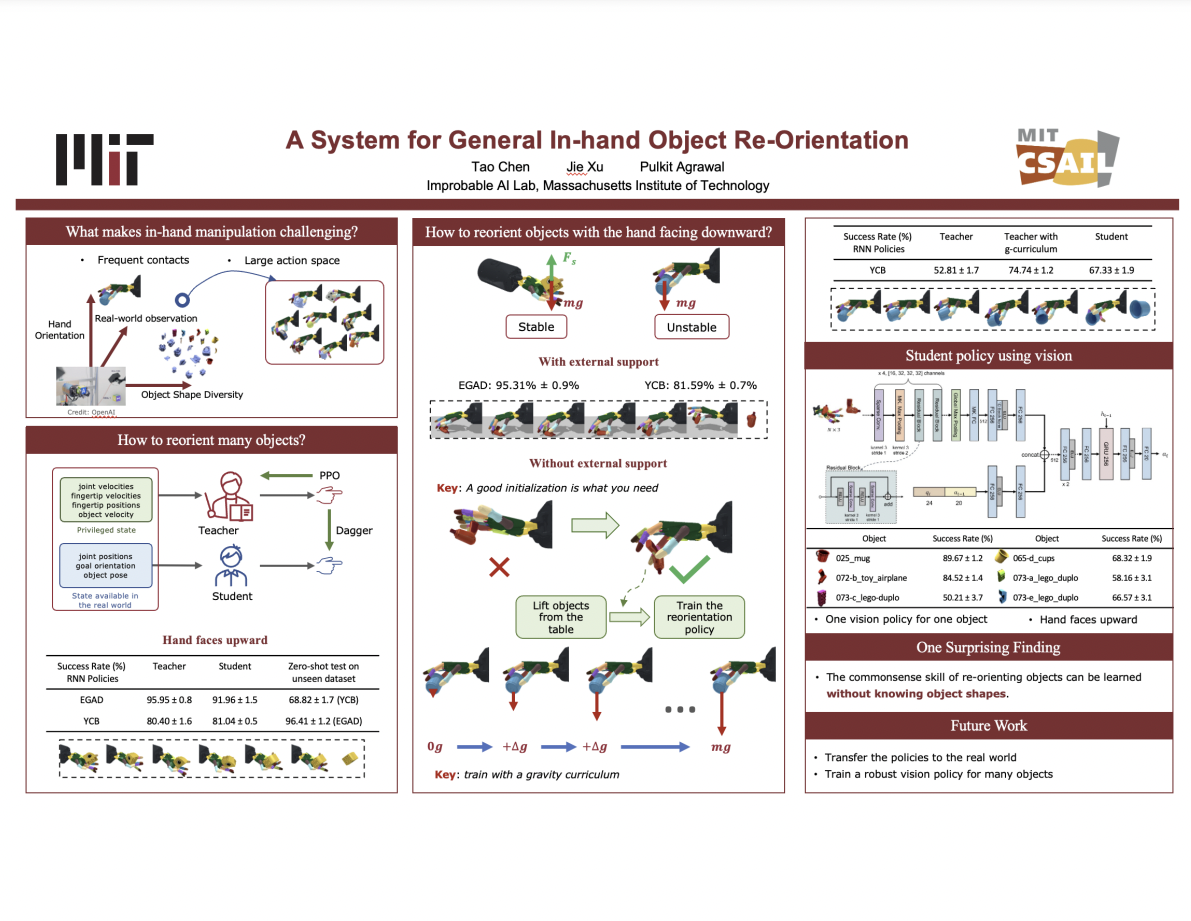
Abstract: Abstract: In-hand object reorientation has been a challenging problem in robotics due to high dimensional actuation space and the frequent change in contact state between the fingers and the objects. We present a simple model-free framework that can learn to reorient objects with both the hand facing upwards and downwards. We demonstrate the capability of reorienting over 2000 geometrically different objects in both cases. The learned policies show strong zero-shot transfer performance on new objects. We provide evidence that these policies are amenable to real-world operation by distilling them to use observations easily available in the real world.
Zied Ben Chaouch | Graduation Date: 08/31/22
PI Lead: Pulkit Agrawal, MIT EECS Assistant Professor

Zied Ben Chaouch is a final year PhD candidate at the MIT Electrical Engineering and Computer Science department’ being advised by Professor Andrew Lo (Sloan School of Management/MIT CSAIL). His interests lie at the intersection of risk management, asset pricing, machine learning, and healthcare finance. He previously completed a Bachelor’s degree at McGill University in Honours Mathematics and Physics, and a Masters degree at MIT in EECS under Professor John Tsitsiklis.
Abstract: Factor models are routinely used in the financial industry to identify and quantify sources of systematic risk to manage the risk of a portfolio of securities and hedge investment positions, or in valuation contexts to estimate the cost of capital of an asset. In this paper, researchers construct latent factor models out of 150 well known factors from the asset pricing literature using autoencoders to explain away most of the anomalies in the cross section of asset prices. They show that their models outperform the classical Fama-French and Hou-Xue-Zhang factor models on a large set of test assets.
Changwan Hong
PI Lead: Julian Shun, MIT EECS Associate Professor
Changwan Hong is a postdoctoral associate at Massachusetts Institute of Technology. He is advised by Professor Julian Shun and Professor Saman Amarasinghe. His research interests include domain specific languages (DSLs), sparse computations, and compiler optimizations.
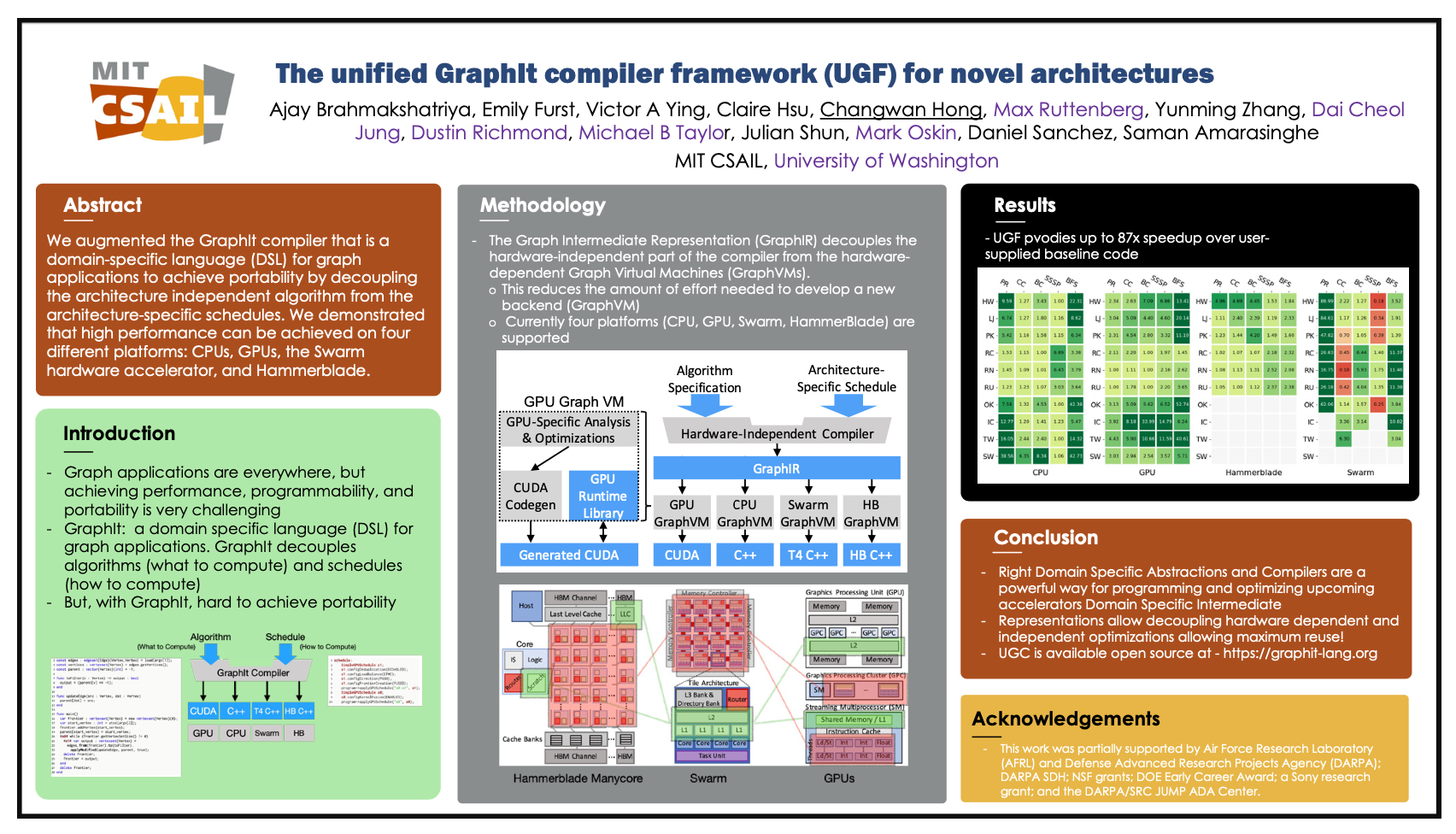
Abstract: Through decoupling the architecture independent algorithm from the architecture-specific schedules, researchers augmented the GraphIt compiler that is a domain-specific language (DSL) for graph ap- plications to achieve portability. They demonstrated that high performance can be achieved on four different platforms: CPUs, GPUs, the Swarm hardware accelerator, and Hammerblade.
Hongyin Luo | Graduation Date: 05/27/2022
PI Lead: James Glass, MIT CSAIL Senior Research Scientist

Hongyin Luo is a Ph.D. candidate at MIT CSAIL. After graduating in May 2022, he will stay at CSAIL and work as a postdoc associate. His research focuses on improving the data efficiency of machine learning based natural language processing models by developing few-shot learning and self-training algorithms.
Abstract: Data annotation is critical for machine learning-based natural language processing models. Although many large-scale corpora and standard benchmarks have been annotated and published, they cannot cover all possible applications. As a result, it is difficult to transfer models trained with public corpora to tasks that require domain-specific knowledge, different inference skills, unseen text styles, and explainability. In this work, we explore self-training methods for mitigating the data distribution gaps between training and evaluation domains and tasks. In contrast to traditional self-training methods that study the best practice of training models with real data and pseudo labels, we also explore the possibility of automatically generating synthetic data for better explainability, robustness, and domain adaptation performance. We show the performance improvement achieved by our methods on the question answering and language inference tasks.
Gabriel Filipe Manso Araujo | Graduation Date: 05/19/2022
PI Lead: Neil Thompson, MIT CSAIL Research Scientist

Gabriel Filipe Manso Araujo is a Research Assistant to Dr. Neil Thompson at MIT’s Computer Science and Artificial Intelligence Lab and the Initiative on the Digital Economy. He holds a bachelor’s degree in Software Engineering from the University of Brasilia. HIs research interests include the economics of artificial intelligence and computing.
Abstract: Deep learning's recent history has been one of achievement: from triumphing over humans in the game of Go to world-leading performance in image recognition, voice recognition, translation, and other tasks. But this progress has come with a voracious appetite for computing power. This article reports on the computational demands of Deep Learning applications in five prominent application areas and shows that progress in all four is strongly reliant on increases in computing power. Extrapolating forward this reliance reveals that progress along current lines is rapidly becoming economically, technically, and environmentally unsustainable. Thus, continued progress in these applications will require dramatically more computationally-efficient methods, which will either have to come from changes to deep learning or from moving to other machine learning methods.
Tal Shnitzer
PI Lead: Justin Solomon, MIT CSAIL Associate Professor

Tal Shnitzer is a postdoc at the Geometric Data Processing group at CSAIL. Her research interests include manifold learning, data fusion, biomedical signal processing and geometric data analysis. Her research is supported by The Eric and Wendy Schmidt Postdoctoral Award for Wom- en in Mathematical and Computing Sciences and by the Viterbi Award, Technion.She received my B.Sc. degree summa cum laude in Electrical Engineering and Biomedical Engineering from the Technion-IIT, Israel, in 2013, and her Ph.D. degree in Electrical Engineering from the Technion in 2020. Her Ph.D., under the supervision of Prof. Ronen Talmon, focused on developing new data-driven manifold learning methods for multi-modal and temporal data analysis.
Abstract: The need for efficiently comparing and representing datasets with unknown alignment spans various fields, from model analysis and comparison in machine learning to trend discovery in collections of medical datasets. We use manifold learning to compare the intrinsic geometric structures of different datasets by comparing their diffusion operators, symmetric positive-definite (SPD) matrices that relate to approximations of the continuous Laplace-Beltrami operator from discrete samples. Existing methods typically compare such operators in a pointwise manner or assume known data alignment. Instead, we exploit the Riemannian geometry of SPD matrices to compare these operators and define a new theoretically-motivated distance based on a lower bound of the log-Euclidean metric. Our framework facilitates comparison of data manifolds expressed in datasets with different sizes, numbers of features, and measurement modalities. Our log- Euclidean signature (LES) distance recovers meaningful structural differences, outperforming competing methods in various application domains.
Nellie Wu | Graduation Date: 06/02/2023
PI Leads: Joel Emer, MIT CSAIL Professor of the Practice | Vivienne Sze, MIT EECS Associate Professor

Nellie (Yannan) Wu is a 5th year Ph.D. candidate at MIT CSAIL advised by professors Joel Emer and Vivienne Sze. Nellie is generally interested in computer architecture research that involves software-hardware co-design. Her projects at MIT focus on modeling and designing hardware accelerators for tensor applications, e.g., deep neural networks.
Abstract: In recent years, many accelerators have been proposed to efficiently process sparse tensor algebra applications (e.g., sparse neural networks). However, these proposals are single points in a large and diverse design space. The lack of systematic description and modeling support for these sparse tensor accelerators impedes hardware designers from efficient and effective design space exploration. This work first presents a unified taxonomy to systematically describe the diverse sparse tensor accelerator design space. Based on the proposed taxonomy, it then introduces Sparseloop, the first fast, accurate, and flexible analytical modeling framework to enable early-stage evaluation and exploration of sparse tensor accelerators. Sparseloop comprehends a large set of architecture specifications, including various dataflows and sparse acceleration features (e.g., elimination of zero-based compute). Using these specifications, Sparseloop evaluates a design’s processing speed and energy efficiency while accounting for data movement and compute incurred by the employed dataflow as well as the savings and overhead introduced by the sparse acceleration features using stochastic tensor density models. Across representative accelerator designs and workloads, Sparseloop achieves over 2000x faster modeling speed than cycle-level simulations, maintains relative performance trends, and achieves 0.1% to 8% average error. With a case study, we demonstrate Sparseloop’s ability to help reveal important insights for designing sparse tensor accelerators (e.g., it is important to co-design orthogonal design aspects).

Mike Foshey
PI Lead: Wojciech Matusik, MIT EECS Associate Professor
Michael Foshey is currently a Staff Mechanical Engineer and Project Manager at MIT Computer Science and Artificial Intelligence Laboratory working with the Computational Design and Fabrication Group and Professor Wojciech Matusik. My research interests focus on building new hardware sensing systems and computational methods that revolutionize how humans and computers sense touch.
Abstract: Daily human activities, e.g., locomotion, exercises, and resting, are heavily guided by the tactile interactions between human and the ground. In this work, leveraging such tactile interactions, we propose a 3D human pose estimation approach using the pressure maps recorded by a tactile carpet as input. We build a low-cost, high-density, large-scale intelligent carpet, which enables the real-time recordings of human-floor tactile interactions in a seamless manner. We collect a synchronized tactile and visual dataset on various human activities. Employing state-of- the-art camera-based pose estimation model as supervision, we design and implement a deep neural network model to infer 3D human poses using only the tactile information. Our pipeline can be further scaled up to multi-person pose estimation. We evaluate our system and demonstrate its potential applications in diverse fields.
Theia Henderson | Graduation Date: 05/01/2026
PI Lead: David Karger, MIT CSAIL Professor
Theia Henderson is a 2nd year PhD student in computer science at MIT CSAIL where she is a member of the Haystack group advised by David Karger. Her research in Human-Computer Interaction is focused on improving social media and other online social tools. As part of her work she builds real-world systems but these practical designs draw inspiration from her background in theoretical computer science.
Abstract: The social spaces we inhabit online are rarely ideal, but there is little we can do to change them without jeopardizing our social connections that exist within them. We introduce a system titled Graffiti that suggests a new ecosystem of online social spaces is possible: one where social data is not siloed into any one specific space. In this ecosystem, users can use whatever in- terfaces, filters, algorithms, moderators and broadcast patterns they see fit. The Graffiti API is sim- ple enough that it is even possible for novice programmers to create or remix social spaces using nothing but HTML and CSS. There is still a separation between contextual spaces in Graffiti --- with- out any separation between our home, work and third spaces we will inevitably experience “context collapse” --- but Graffiti’s power comes from its ability for data to exist in large sets of spaces all at once and these sets need only intersect, not overlap, with the set of spaces that someone observes to facilitate communication.