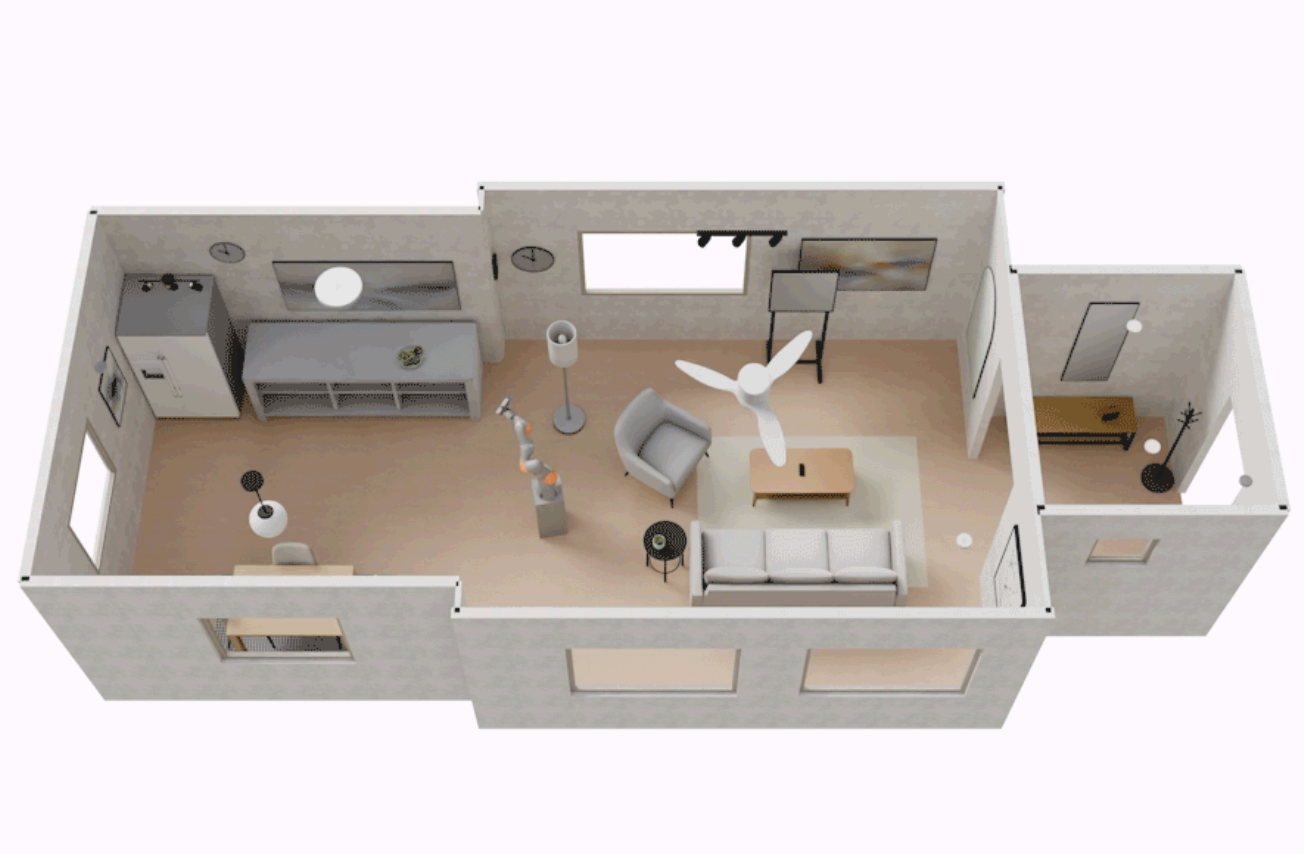
SceneSmith, a new system developed at MIT uses three agents to piece together the objects, walls, and overall look of a 3D scene. Its realistic recreations of indoor spaces help robots practice skills and try out different ways of doing tasks before they’re powered on.