Computer graphics and geometry processing research provide the tools needed to simulate physical phenomena like fire and flames, aiding the creation of visual effects in video games and movies as well as the fabrication of complex geometric shapes using tools like 3D printing.
As artificial intelligence models become increasingly prevalent and are integrated into diverse sectors like health care, finance, education, transportation, and entertainment, understanding how they work under the hood is critical. Interpreting the mechanisms underlying AI models enables us to audit them for safety and biases, with the potential to deepen our understanding of the science behind intelligence itself.
As a child, I often accompanied my mother to the grocery store. As she pulled out her card to pay, I heard the same phrase like clockwork: "Go bag the groceries." It was not my favorite task.
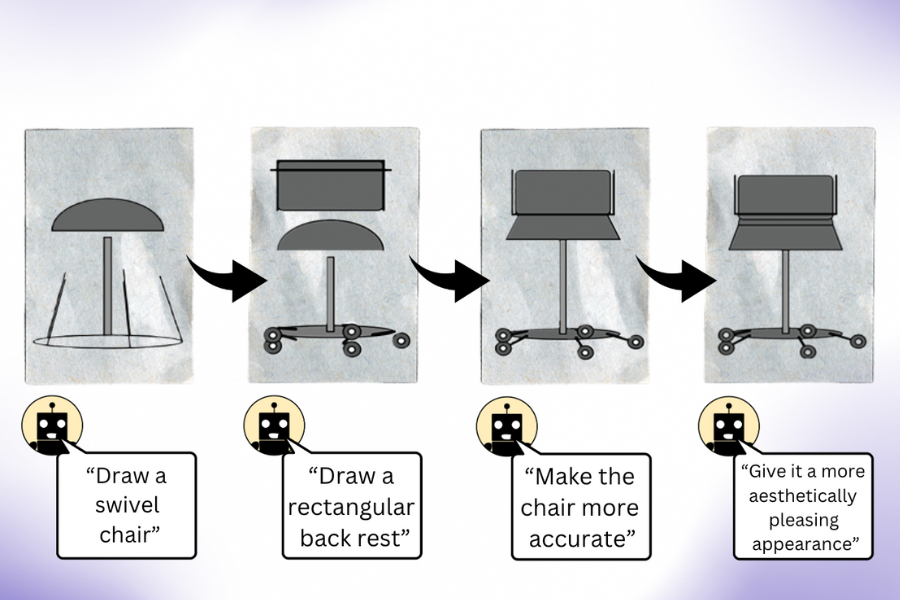
Someday, you may want your home robot to carry a load of dirty clothes downstairs and deposit them in the washing machine in the far-left corner of the basement. The robot will need to combine your instructions with its visual observations to determine the steps it should take to complete this task.
Mark Hamilton, an MIT PhD student in electrical engineering and computer science and affiliate of MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL), wants to use machines to understand how animals communicate. To do that, he set out first to create a system that can learn human language “from scratch.”
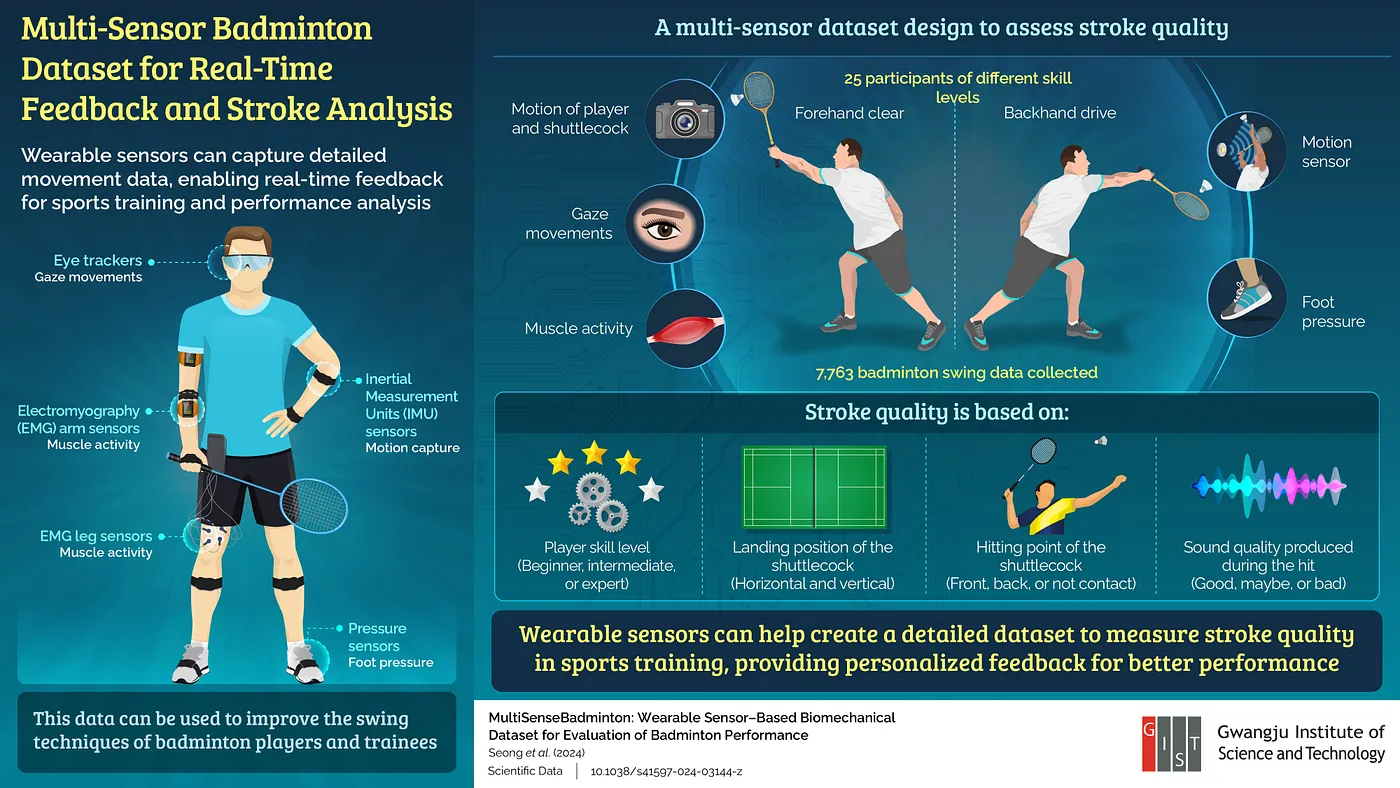
In sports training, practice is the key, but being able to emulate the techniques of professional athletes can take a player’s performance to the next level. AI-based personalized sports coaching assistants assist with this by utilizing published datasets. With cameras and sensors strategically placed on the athlete's body, these systems can track everything, including joint movement patterns, muscle activation levels, and gaze movements.
The internet is awash in instructional videos that can teach curious viewers everything from cooking the perfect pancake to performing a life-saving Heimlich maneuver.