Learn about Khosla Ventures and their portfolio companies, and what kinds of technologies they see as a good fit for investment.
Khosla Ventures, a member of CSAIL Alliances, is coming to MIT CSAIL to talk about the technologies KV invests in and the technologies that are interested in collaborating with at CSAIL.
Add to calendarAmerica/New_YorkTech Talk with Khosla Ventures09/23/2026
Learn about Khosla Ventures and their portfolio companies, and what kinds of technologies they see as a good fit for investment.
Khosla Ventures, a member of CSAIL Alliances, is coming to MIT CSAIL to talk about the technologies KV invests in and the technologies that are interested in collaborating with at CSAIL.
Andrew W. Lo, MIT Professor in the Sloan School of Management, CSAIL PI, and Faculty Co-Director of FinTechAI@CSAIL, says, "The question is: `Do large language models have our back?’ The answer is no, not yet.”
An increasingly common sight: robots walking down the street, surrounded by astounded onlookers. But these machines aren’t yet the do-it-all assistants you’d want working in a kitchen or factory, and a major bottleneck is data. Much like humans, robots learn best by experience. The challenge is that it’s labor-intensive and time-consuming to physically teach these machines so many actions across different settings.
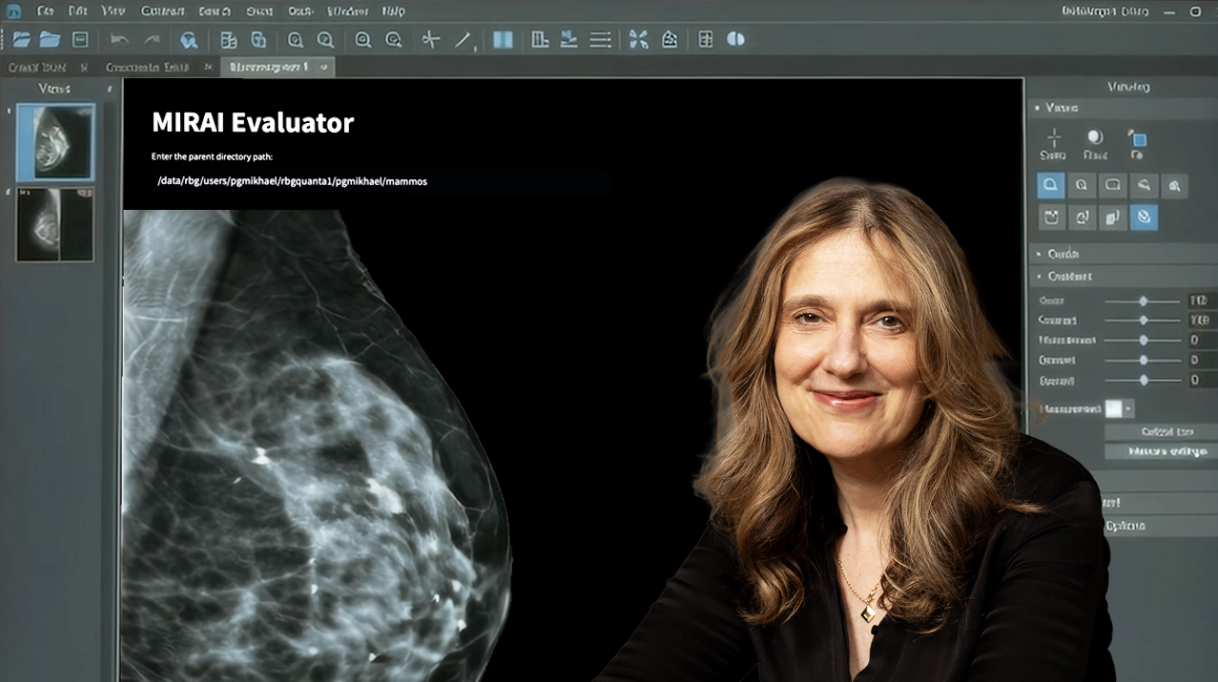
An algorithm flags a patient as high risk for sepsis; a risk score informs whether a woman receives additional cancer screening; a deterioration model triggers an alert that sends a care team to a bedside.
To accelerate and refine decision-making in a fast-paced, global marketplace, enterprises may deploy generative artificial intelligence models to help summarize and interpret the charts that often fill market summaries and financial reports.
For MIT Professor Armando Solar-Lezama, one of the most common misunderstandings about AI is the notion that it can be dropped into existing human roles like a plug-and-play replacement.
David Clark, Senior Research Scientist at MIT CSAIL, helped design the system that connects nearly every computer on earth. As Chief Protocol Architect of the Internet from 1981 to 1989, he was there for the beginnings of the Internet. Calling the wave of AI technology an “echo” of what happened in the 80’s, Dr. Clark is cautioning, “ maybe we need to slow things down and think a bit.”
What happens when the team behind PlayStation meets the researchers pushing the boundaries of AI? You get The Nexus of Games and AI, a 12-part MIT Independent Activities Period (IAP) course, now available to stream.