Please join the Annual AI & Quantum Summit, hosted by CSAIL Alliances and the MIT Center for Quantum Engineering (MIT CQE). This event is in-person at MIT with a virtual option.
On October 23rd, 2025, CSAIL and MIT experts will gather to explore how the field of quantum computing is changing, how AI innovation is molding quantum’s trajectory, and what business leaders should keep in mind as theory becomes reality.
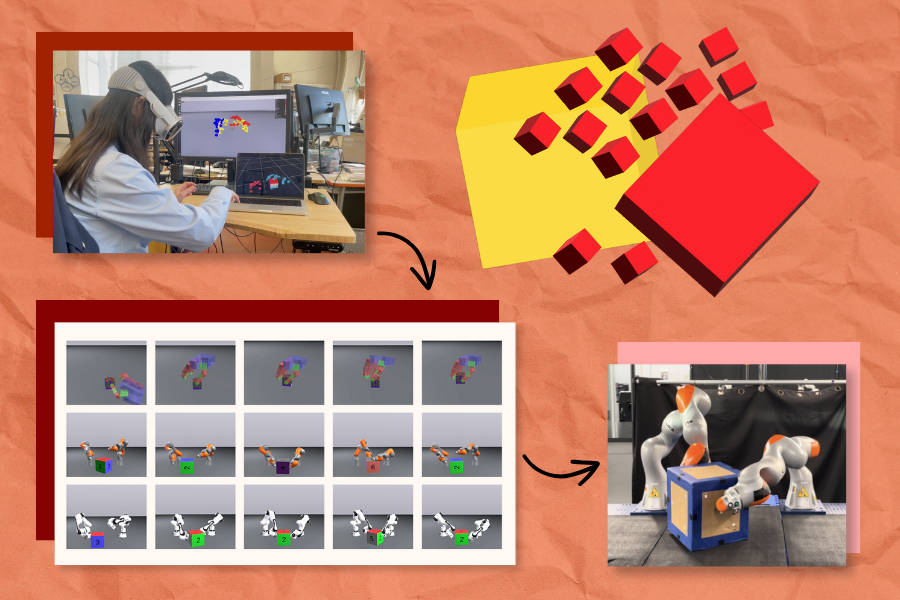
Imagine a future where artificial intelligence quietly shoulders the drudgery of software development: refactoring tangled code, migrating legacy systems, and hunting down race conditions, so that human engineers can devote themselves to architecture, design, and the genuinely novel problems still beyond a machine’s reach. Recent advances appear to have nudged that future tantalizingly close, but a new paper by researchers at MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and several collaborating institutions argues that this potential future reality demands a hard look at present-day challenges.
When ChatGPT or Gemini gives what seems to be an expert response to your burning questions, you may not realize how much information it relies on to give that reply. Like other popular artificial intelligence (AI) models, these chatbots rely on backbone systems called foundation models that train on billions or even trillions of data points.
MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) has announced a new direction for its long-standing FinTech research initiative, now FinTechAI@CSAIL, to highlight the central role artificial intelligence is playing in shaping the future of finance.
Marine scientists have long marveled at how animals like fish and seals swim so efficiently despite having different shapes. Their bodies are optimized for efficient aquatic navigation (or hydrodynamic) so they can exert minimal energy when traveling long distances.
Research has shown that large language models (LLMs) tend to overemphasize information at the beginning and end of a document or conversation, while neglecting the middle.
The Hertz Foundation announced that it has awarded fellowships to eight MIT affiliates. The prestigious award provides each recipient with five years of doctoral-level research funding (up to a total of $250,000), which gives them an unusual measure of independence in their graduate work to pursue groundbreaking research.
When you’re trying to communicate or understand ideas, words don’t always do the trick. Sometimes the more efficient approach is to do a simple sketch of that concept — for example, diagramming a circuit might help make sense of how the system works.
But what if artificial intelligence could help us explore these visualizations? While these systems are typically proficient at creating realistic paintings and cartoonish drawings, many models fail to capture the essence of sketching: its stroke-by-stroke, iterative process, which helps humans brainstorm and edit how they want to represent their ideas.
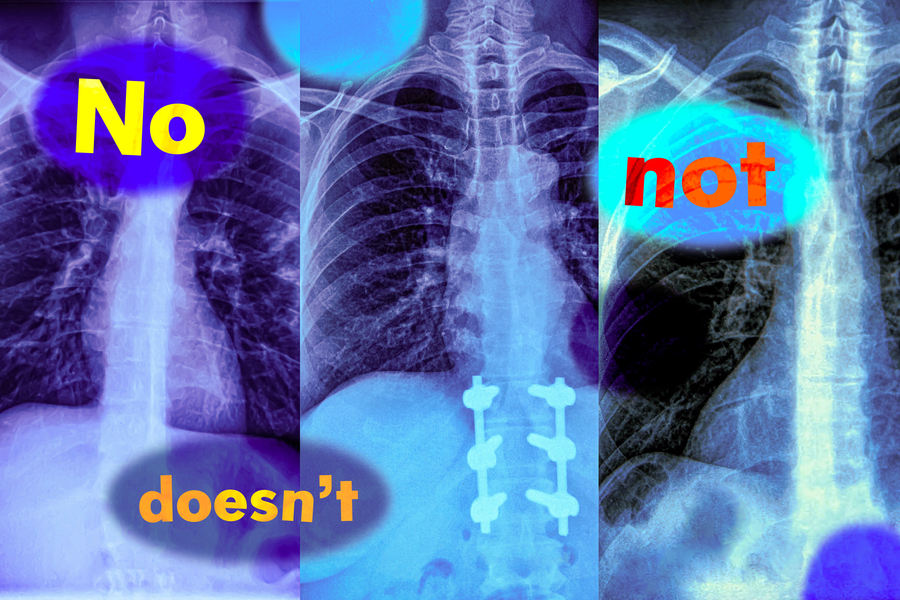
Imagine a radiologist examining a chest X-ray from a new patient. She notices the patient has swelling in the tissue but does not have an enlarged heart. Looking to speed up diagnosis, she might use a vision-language machine-learning model to search for reports from similar patients.
Essential for many industries ranging from Hollywood computer-generated imagery to product design, 3D modeling tools often use text or image prompts to dictate different aspects of visual appearance, like color and form. As much as this makes sense as a first point of contact, these systems are still limited in their realism due to their neglect of something central to the human experience: touch.