Ready for that long-awaited summer vacation? First, you’ll need to pack all items required for your trip into a suitcase, making sure everything fits securely without crushing anything fragile.
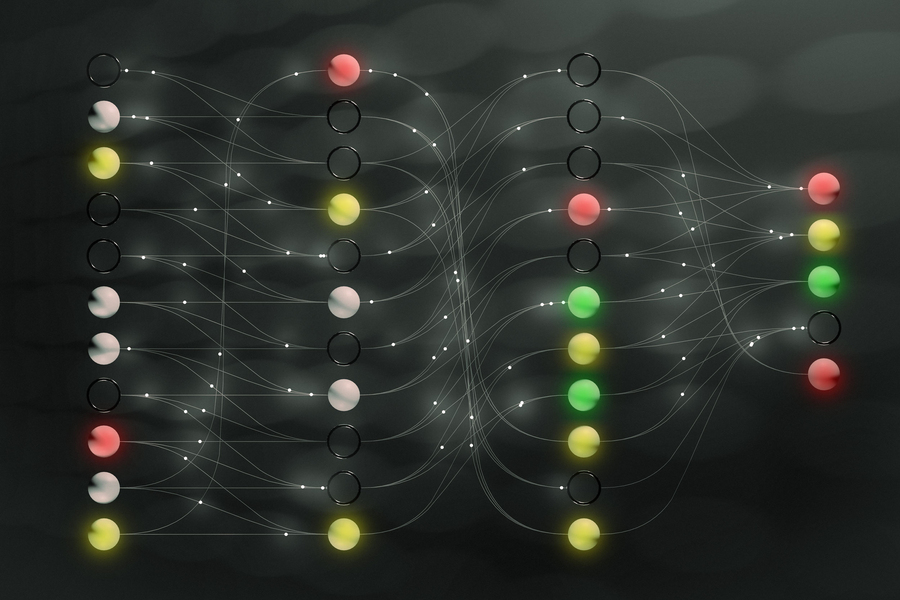
Given the recent explosion of large language models (LLMs) that can make convincingly human-like statements, it makes sense that there’s been a deepened focus on developing the models to be able to explain how they make decisions. But how can we be sure that what they’re saying is the truth?
Artificial intelligence systems like ChatGPT provide plausible-sounding answers to any question you might ask. But they don’t always reveal the gaps in their knowledge or areas where they’re uncertain. That problem can have huge consequences as AI systems are increasingly used to do things like develop drugs, synthesize information, and drive autonomous cars.
The Hertz Foundation announced that it has awarded fellowships to eight MIT affiliates. The prestigious award provides each recipient with five years of doctoral-level research funding (up to a total of $250,000), which gives them an unusual measure of independence in their graduate work to pursue groundbreaking research.
When you’re trying to communicate or understand ideas, words don’t always do the trick. Sometimes the more efficient approach is to do a simple sketch of that concept — for example, diagramming a circuit might help make sense of how the system works.
But what if artificial intelligence could help us explore these visualizations? While these systems are typically proficient at creating realistic paintings and cartoonish drawings, many models fail to capture the essence of sketching: its stroke-by-stroke, iterative process, which helps humans brainstorm and edit how they want to represent their ideas.
Buy-Side Equity Quant Analysis: Tools and Open Problems, featuring BAM
The distance between a finance academic and a finance practitioner is quite large, especially if the practitioner works for a prop trading firm or a hedge fund. In this talk I will talk about some of the tools of the trade in use by buy-side firms, some of the open problems they face. Time permitting, I will briefly discuss modeling crowding phenomena, backtesting protocols, challenges to factor models and spiked covariance matrices, aggregation and attribution of large signal sets, and portfolios from ranks.
Humans naturally learn by making connections between sight and sound. For instance, we can watch someone playing the cello and recognize that the cellist’s movements are generating the music we hear.
Diffusion models like OpenAI’s DALL-E are becoming increasingly useful in helping brainstorm new designs. Humans can prompt these systems to generate an image, create a video, or refine a blueprint, and come back with ideas they hadn’t considered before.
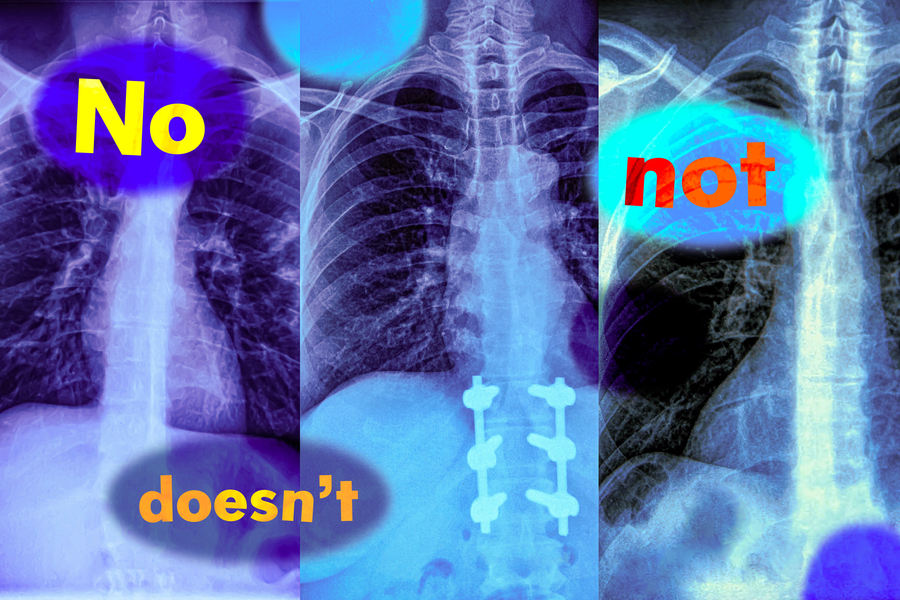
Imagine a radiologist examining a chest X-ray from a new patient. She notices the patient has swelling in the tissue but does not have an enlarged heart. Looking to speed up diagnosis, she might use a vision-language machine-learning model to search for reports from similar patients.