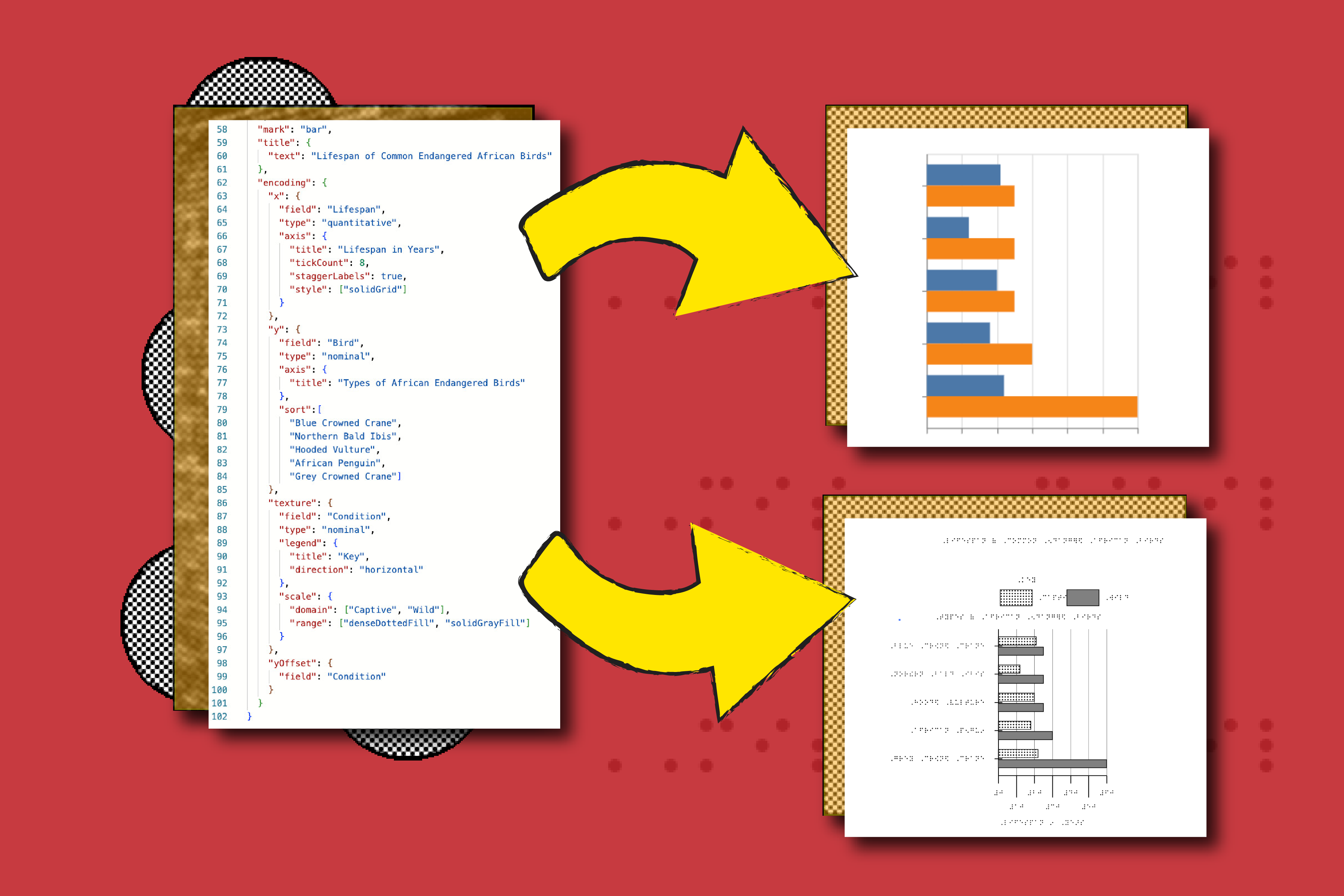
Bar graphs and other charts provide a simple way to communicate data, but are, by definition, difficult to translate for readers who are blind or low-vision.
More than seven years ago, cybersecurity researchers were thoroughly rattled by the discovery of Meltdown and Spectre, two major security vulnerabilities uncovered in the microprocessors found in virtually every computer on the planet.
CSAIL Alliances Affiliate Member Sony Interactive Entertainment (SIE) hosted a January 2025 IAP course, “The Nexus of Games and AI.” Designed to “introduce students to game creation, current game-related research, and an exploration of the technology, the art, and the fun of video games,” this course allowed SIE to engage with a broad range of students, meet CSAIL faculty, and deepen their connection to MIT CSAIL.
20 years ago in a pre-ChatGPT world, a fake-paper generator created by 3 MIT kids fooled a major conference so badly that they had to completely reconfigure their reviewing practices.